
Take me to...

Research Scientist - Deep Learning
Piotr is a Research Scientist working in the Deep Learning team at Featurespace. His work involves keeping up with recent advancements in deep learning, as well as designing, prototyping and testing new algorithms based on neural networks. Piotr's background is in physics - having completed a PhD on spintronics in organic semiconductors at Cambridge University. Loves cooking, baking, and anything to do with food, sweet or savoury.
The key to effective deep learning research is rapid conduction of a large number of experiments. First, you try to build a theoretical understanding of the problem at hand, then you prototype a solution and test how well it works. The testing part is often trying out different configurations of neural network structures and hyperparameters to see which ones work the best, and how performance scales with the different parameters. Being able to train your models quickly is therefore crucial for efficient research.
To this end, the first thing that you need to ensure is high performance hardware (i.e. containing many Graphics Processing Units (GPUs)) and infrastructure that lets you utilize their full power. That includes a job scheduler to orchestrate running code from multiple users, and an efficient model training pipeline which ensures full GPU utilization, e.g. by caching pre-processed inputs and prefetching them.
To further speed up training you could of course source more GPUs, but that’s rather costly. A better way forward is to optimize your neural network architecture or training strategy. That’s what we did at Featurespace, and the results have been quite striking. After developing a better understanding of the nuances of neural network optimisation, we managed to speed up training on GPUs by a factor of 10. Without changing anything about our infrastructure, we were instantly able to conduct 10 times as many experiments as before, and answer many more questions about designing the best possible fraud detection models.
To understand what we did and why it worked, let’s talk about the standard way of training neural networks: gradient optimization. The basic principle is the following; start with a loss function that measures how distant your model predictions are from the ground truth – the smaller this loss, the better your model is at predicting. Training your network can be seen as taking incremental steps down the loss landscape defined in a highly dimensional space of parameters. Making a step downhill is equivalent to changing model parameters slightly in a way that reduces the loss. How do you decide which way is downhill? You can follow the gradients of the loss function with respect to the network parameters – these gradients point in the direction of the steepest descent, i.e. the fastest way towards a (local) minimum.
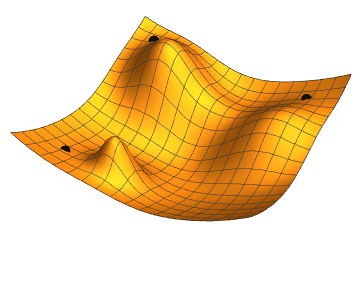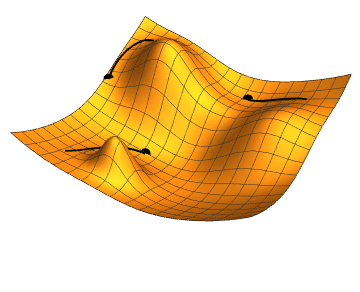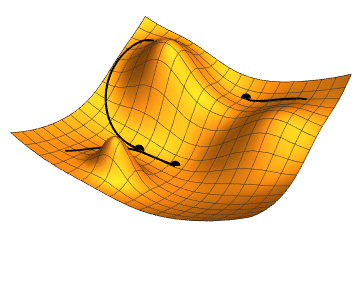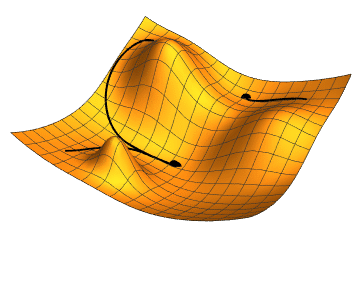
Figure 1 Source: Jacopo Bertolotti, CC0, via Wikimedia Commons
The most basic algorithm that implements an approximation of the above optimization is called minibatch stochastic gradient descent (SGD). At each iteration it approximates the value of loss by computing it on a small random batch of data rather than the whole dataset, therefore the gradients are also approximate and contain a certain amount of stochastic noise (random probability distribution or patterns that may be analysed statistically, but may not be predicted precisely). It has two main hyperparameters: batch size and learning rate.
The batch size defines how many data points to sample from the dataset for each gradient estimation. Small batch sizes give gradient estimates that are imprecise and noisy. While each step might not point in the most optimal direction, the effect of noise should average out after multiple updates. Larger batch sizes provide more representative samples from the dataset, hence more precise gradient estimates with less noise. It seems that large batch sizes should be preferred, but there are often good reasons to choose smaller ones. Gradient computation scales with model size and batch size, therefore smaller batches are easier to manage within GPU memory restrictions, especially for large models. Also, the noise associated with smaller batch size has a regularising effect that helps the model generalise to unseen data. Typically, a batch size is set to a small value such as 32 or 64 (a power of 2).
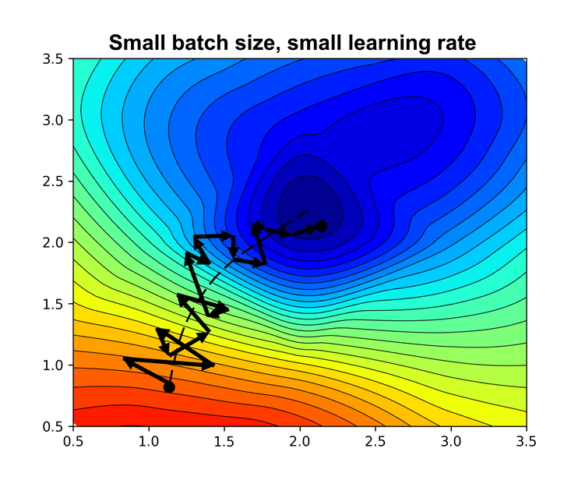
The learning rate defines the size of the step in the direction of loss gradient. If its value is too small, then training will take a very long time to complete and might get stuck in a suboptimal local solution which does not generalise well. The larger it is, the faster the rate of convergence and the lower the training time. However, if it’s too large, then the algorithm might never be able to converge to a particular solution and the final model performance might be suboptimal. It will also amplify noise in gradient estimation, causing the risk of gradient steps overshooting in the wrong direction or in extreme cases diverging. Very often one picks a constant learning rate that maximizes performance on a validation set. Practitioners typically favour extensions of SGD that compute adaptive learning rates, with Adam being the most popular one. Learning rate schedulers are also popular, such as annealing or cyclical scheduling – they can improve model performance and reduce training time to some extent. But in general, it’s not straightforward to speed up training by simply increasing learning rate without sacrificing model performance.
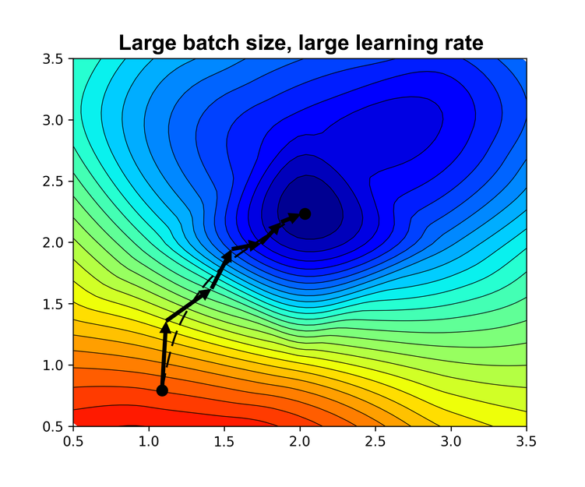
We should also keep in mind that considering and optimizing different hyperparameters in isolation won’t work well if they are coupled. It shouldn’t be surprising that learning rate and batch size are tightly coupled, since the amount of noise induced by small batch size effectively limits how much we can increase learning rate before running into training instabilities. An interesting perspective on this can be learnt from a paper published last year by DeepMind on the implicit regularisation properties of SGD. According to the DeepMind research, the stochastic nature of SGD imposes an implicit regularization term that encourages the model to find more generalizable solutions which have better performance on the holdout test set. Specifically, they found out that the strength of this term is proportional to the ratio of the learning rate to the batch size. This means that if you vary only one of these parameters, you will invariably change the magnitude of the implicit regularization, which can cause the model to underfit or overfit. It also suggests that in order to keep the implicit regularization balanced, you should increase/decrease both parameters at the same time.
This observation gave us an idea that that we might be able to speed up training on GPUs without loss of performance if we train our models using high learning rate and large batch size. We were confident in this approach in part because GPUs have excellent parallel processing architecture, e.g. on NVIDIA A100 increasing batch size 32 times extends its processing time by only a factor of 2. Then, increased learning rate and reduced noise from gradient updates should reduce the number of iterations required to optimize a model, which should more than compensate for the slight increase in batch processing time. All of this was of course based on the assumptions that the results from the paper would still hold if we used Adam (an improved version of SGD with adaptive learning rates).
This approach was incredibly effective. Increasing batch size from 128 to 4,096 let us increase the learning rate and as a consequence reduce training time by a factor of 10. At the same time, we didn’t observe any drop in performance on the validation set, which suggests that our theory about balancing the overall implicit regularization is correct. It’s worth pointing out that increasing batch size by a factor of 32 is not so trivial if you use large models and data with plenty of features. In the payments fraud space where Featurespace operates, the sequential transaction data has a fairly low dimensionality, and the online latency requirements constrain the size of models we can put into production. Therefore, even batches of sizes as big as 4,096 could fit into the memory of a single GPU.
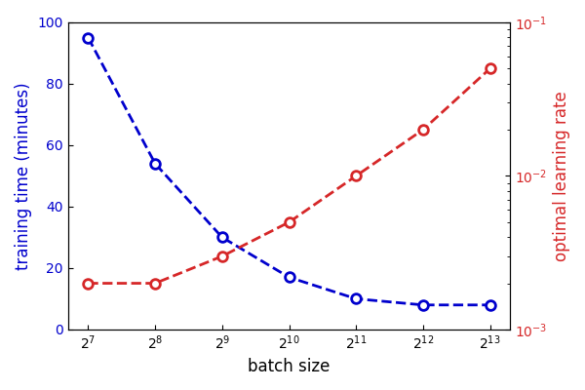
Reducing model training time drastically improved the quality of research that our team conducts. Being able to train 10 times as many models as before, let us explore different ideas in more depth without having to prioritize testing only the most promising hypotheses. We could also perform more runs of the same experiment, get better estimates of variance in performance, and better judge the statistical significance of the results. Consequently, this improved the value of solutions that our data science team delivers to customers.
The idea of training with large batch size and learning rate is quite established. In 2018, Facebook published a paper on using this strategy to train an image model on over 1 million images in a surprisingly short amount of time. In order to use large batch sizes, however, they spread training across 256 GPUs – a feat that to these days is still only achievable by few big companies. It’s quite understandable that in the vast majority of cases where models are trained or fine-tuned on downstream tasks, resources are limited. And even if an organization potentially has the resources to increase the batch size, the prevalence of papers and projects using default batch sizes of 32 or 64 creates a sort of confirmation bias that doesn’t really encourage looking for alternatives. The lesson to learn here is that as a research scientist it is important to both understand and at the same time question the technological status quo. Finding balance between trust, scepticism, and openness to doing things differently might just be the way to discovering new solutions.
It is quite remarkable how batch size and learning rate are perhaps the two most basic hyperparameters in deep learning, yet there’s still research being done to understand their full impact. It has been a fairly common practice in deep learning to build intuition based on experimental observations, and only afterwards answer the more difficult question: ‘How does it actually work?’. With the ability to explain the inner workings of empirically observed phenomena, there is a potential to redesign and improve the best practices, even those that have been considered well established.
Piotr Skalski is a Research Scientist specializing in Deep Learning at Featurespace, a fintech preventing payments fraud and financial crime with machine learning.

 by
by