
Take me to...

Every time somebody makes a credit card transaction, the transaction is sent to a fraud detection platform, which decides whether to approve or decline the transaction. The best fraud detection platforms use machine learning. A machine learning model draws upon a variety of predictive signals to make its prediction. Some of the most important predictive signals pertain to human behavior over the course of time. For this reason, the model requires information not just about the current transaction, but also about past transactions that took place over the minutes, hours, days, and months prior to the current transaction.
A feature store is a software component that supplies machine learning models with contextual information about how people behaved in the past. In the fraud detection example, a feature store might provide the model with information about how much a cardholder typically spends, or which shops are the cardholder’s favorites, or whether the shop that the cardholder is currently shopping at is in the middle of a fraud attack.
In this post, we’ll explain what we mean by a feature store, and describe the qualities of a feature store that are important for fraud detection.
A feature store is a software component that supplies machine learning models with contextual information about how people behaved in the past.
Look at the following transaction. Do you think this transaction is fraudulent?
{
card: 123192391828,
merchant: “Ace Stores”,
amount: $100,
timestamp: “2022-05-04 12:12:42”
}
It is difficult to tell whether this transaction is fraudulent just by looking at the information in the transaction itself. You may be wondering whether $100 is a typical or atypical amount for the cardholder to spend – but how can you assess this if you know nothing about the cardholder’s past spending behavior?
To determine whether this transaction is fraudulent, it is extremely useful to have access to state variables that summarize salient properties of transactions that took place in the past.
{
currentTransaction: {
card: 123192391828,
merchant: “Ace Stores”,
amount: $100,
timestamp: “2022-05-04 12:12:42”
}
stateVariables: {
highestAmountSpentOnCardOverLastMonth: $10,
numberOfTransactionsOnCardOverLastMinute: 16
}
}
Different people mean different things by the term feature store. For us, a feature store has two key responsibilities, which we will elaborate on below:
1. Computing up-to-date state variables and serving these state variables to real-time models at inference time.
2. Computing state variables at historical points in time in order to train models on historical data.

Overall, the feature store makes state variables available to models at training time and inference time. Using these state variables, it is possible to construct model features that draw upon signals from both the present and the past.
State variable: The highest amount spent on the card over the last month.
Feature constructed from this state variable: The current transaction amount divided by the highest amount spent on the card over the last month.
Signal captured by this feature: The card is being used to make transactions that are atypically large relative to the normal behavior for the cardholder.
It is a little confusing that a feature store serves states, rather than serving the features constructed from those states. It is equally confusing that a feature store is responsible for computing state values, rather than merely storing state values that have been computed elsewhere. Arguably, a feature store should be called a “state calculator”!
But “feature store” is the established terminology in the machine learning community, so that is the terminology we will stick with.
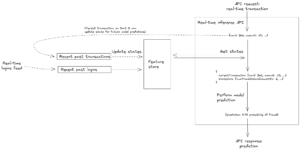
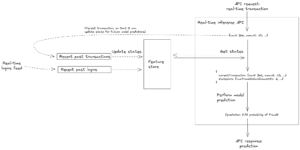
Suppose the data scientist wishes to incorporate a feature into their model to identify whether the value of the current transaction is atypically large for the cardholder. A data scientist would register in the feature store a state variable defined to be the highest amount spent by the cardholder over the last month, since this state variable is needed to construct the feature. It is then the feature store’s responsibility to calculate the values of this state variable for each cardholder, to keep these state values up to date over time, and to make these state values available to machine learning models at inference time.
If the fraud detection platform takes too long to respond to a transaction, then the cardholder will be kept waiting at the till. Part of the time taken to process a transaction is spent in retrieving the relevant state values from the feature store. Therefore, it is essential that the feature store responds quickly every time state values are requested.
To protect against certain kinds of bot-initiated fraud attacks, it may be useful for the model to include a feature that tracks the number of transactions that took place on the card over the last minute. What’s important here is that the model sees an up-to-date value for this feature. If the feature value is out of date by several minutes, then obviously the feature is of no use to the model.
Uptime is critical for a fraud detection platform. Every second the platform is down, is a second where a fraudster can commit fraud unchecked. The feature store, being part of this critical infrastructure, should be resilient to hardware failures. If a component of the hardware fails, then some other hardware component should be at hand to take over.

Uptime is critical for a fraud detection platform. Every second the platform is down, is a second where a fraudster can commit fraud unchecked.
If a hardware component does fail, then the hardware component that takes its place should pick up from where the failed component left off. Naïve implementations of state updates might miss or double-count state updates from transactions during a failover. A good feature store should have mechanisms in place to guarantee that each transaction contributes once and only once to the state.
The computational load on the feature store varies over time. There are fewer transactions at 3:00 am than at 5:00 pm; similarly, there are fewer transactions on a Sunday in January than on a Friday leading up to Christmas. Feature stores should scale to meet variable (and sometimes unpredictable) throughput requirements.
An extreme example of this is where the feature store needs to update its state values from daily or weekly batch files. These batch files may contain raw data that is difficult to deliver in real-time due to data engineering constraints, or they may contain derived data that is the result of executing analytical computations such as network analytics. These batches may need to be processed in a short time window. For large batches, this would be hard to achieve unless the feature store can scale its throughput in response to changes in demand.
Some features in the model may have a long lookback period – for example, a feature that measures the total spending by the cardholder over the last month.
Making such a feature available to the model is beset with practical challenges. The naïve approach is to initialize each cardholder’s total spending at zero in the feature store, then wait for these totals to accumulate over time. But if we did that, then we would have to wait a whole month before the feature is accurate and usable!
The solution to this problem is called “backfill”. Backfill is an operation that initializes the state values in the feature store so that the new feature is usable immediately. To backfill the cardholder’s total spending over the last month, the feature store would perform a fast retrospective sweep over historical transactions from the past month, thus initializing the state values in the feature store. A feature store should be able to perform this backfill operation at high throughput, without exposing the data scientists to the engineering complexity of implementing this operation.
In the previous section, we described how feature stores calculate and serve state values to models at inference time. But model inference is not the only part of the machine learning lifecycle where state values are needed!
At model training time, it is just as necessary to calculate state values. State values must be calculated for every datapoint in the training set, and it is the responsibility of the feature store to perform this calculation.
The state values calculated for model training are point-in-time state values. Every datapoint in the training set corresponds to some transaction that happened in the past, so the states calculated for that transaction must be accurate as of the time when the transaction happened.
It’s essential that the state calculation logic used for model training is identical to the logic used during real-time model inference. Since the same feature store is being used at training time and at inference time, the data scientist can be confident that the state calculation logic is consistent.
A classic problem encountered by homegrown alternatives is accidentally incorporating information from Tuesday into the state values for a transaction in the training dataset that took place on Monday. At training time, the model will learn to use the information pulled from the future – but at inference time, it is impossible to pull information from the future

For the model training experience to be a pleasant one, these point-in-time state calculations should run at high throughput. Ultimately, the most expensive resource is the time that the data scientist spends at their desk. The faster a data scientist can calculate point-in-time state values, the sooner they can iterate on their models and the more productive they will be overall.
A feature store is a software component that supplies state variables to machine learning models at training time and inference time.
Without a feature store, a data scientist must implement the logic of the state calculations from scratch. It might take months just to stand up a working version that calculates the state variables correctly. It would take even longer to produce a version that is both performant enough for the data scientist to train, deploy and backfill many iterations of their models over the course of a working week, and also mature enough to satisfy production requirements around latency, state freshness, resiliency and scalability.
Given a feature store like the one outlined in this article, a data scientist does not need to think about these technicalities. They can focus purely on the data science aspect of their work – rapidly iterating on their models as new signals emerge in the data or as business requirements evolve.

 by
by