
As a Senior Data Scientist at Featurespace, I’ve looked through a lot of applications for people starting out their careers in data science. I’ve read hundreds of CVs and worked on many of the phone interviews, take-home tests, and in-person interviews that make up the rest of our hiring pipeline. I also ran the data science internship programme at Featurespace in 2022, for which we had more than 300 applicants. This is all to say that, while I can’t claim to have universal insight into how to get any data science job at any company, I have a pretty good sense of what makes an applicant successful when applying for data science at Featurespace.
Over time, I’ve come up with some general principles for getting started in data science. I’m hoping they will be useful to people looking to stand out from the crowd.
What You Need to Know
Before you apply to a position, you’ll need to build up an understanding of data science. Whether through coursework or self-study, you need to build a foundation. Unfortunately, “data science” can cover a pretty wide range of topics, including querying databases, writing ETL pipelines, and building machine learning models. This article will assume that you’re interested in a career that includes building machine learning models, which is the job of a data scientist at Featurespace.
The .fit/.predict Data Scientist
There seems to be an explosion in the number of data science programmes in the last few years, particularly data science masters’ courses. This makes sense; data is really important to how many modern businesses run. However, I’m not convinced that these programmes are always providing the best foundation for their graduates. In general, they seem to heavily emphasise breadth over depth. This has coincided with libraries like sklearn or TensorFlow becoming increasingly slick, which can combine to create what I’ve started to call the .fit/.predict data scientist. Students are asked to jump from algorithm to algorithm, with very little time to catch their breath, and end up just repeatedly writing something like the following:
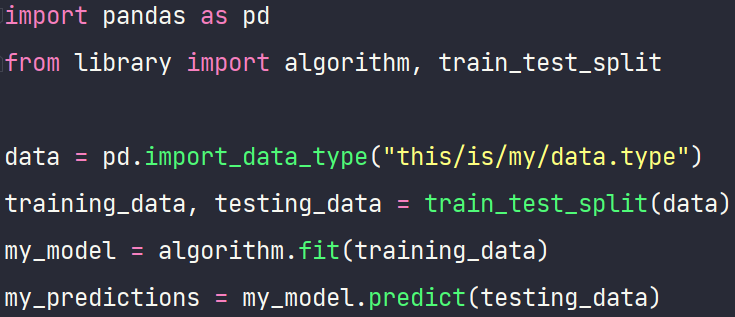
Obviously, I’m oversimplifying but my general point is that people tend to stay with an algorithm just long enough to ask a magical black box to product some results and then move on. Unfortunately, this does very little to teach data science!
Becoming a Specialist
My advice for anyone in this position is to take a step back. There’s no way you’ll ever stay on top of every algorithm and you’ll run yourself ragged trying. Even just the list of neural networks can be overwhelming. Here’s what I recommend instead:
- Start by building yourself a machine learning map, something like the sklearn estimator map or data iku’s introduction to machine learning. Do actually take the time to make this yourself and to build it out as you go. You should organise it in a way that makes sense to you, which might change over time.
- For the vast majority of algorithms you come across, just pop them on the map. You want to know roughly:
- What will you get as an output: a class, a value, a cluster?
- What does it typically take as input data: tabular data, images, language?
- Does your data need to be labelled?
- What is this algorithm’s one-line “claim to fame”? In other words, why should you care?
- When is this algorithm probably a bad choice?
Let’s take the example of a logistic regression model. You could write that you’ll get out a class – in the simplest case it’s a binary classifier but you can get multiclass classification too. Most commonly this is used with tabular data and that data must be labelled. It’s famous as the simplest machine learning classifier and simplicity is really not to be underestimated. However, for more complicated problems it probably won’t give you the best performance. I now have three sentences I need to remember about logistic regression; for the vast majority of things you come across, I genuinely think this is enough. As and when you need to use these algorithms, you’ll get to know them better.
What about becoming a specialist? I recommend picking two algorithms, beyond linear and logistic regression, and really getting to know them end to end. The first place I would start is actually YouTube – there are loads of great videos out there. I’ve put together a data science boot camp in Featurespace, which is designed to take people with a technical background and get them up to speed in data science, and I relied quite heavily on YouTube. I also recommend Andriy Burkov’s The Hundred-Page Machine Learning Book.
For the algorithms you specialise in, you should know the following (in addition to the points mentioned above):
- How does the algorithm itself work, in detail?
- What is the main idea behind setting up this algorithm?
- How would you draw this algorithm if you wanted to explain its architecture?
- What is the algorithm’s loss function (or equivalent)?
- How is the algorithm trained? For example, does it use backpropagation or does it rely on another method?
- If this algorithm has intermediate stages (layers in a neural network, trees in a forest, etc.), how would you interpret those intermediate stages?
- How do you preprocess data before passing it to the algorithm? How does this algorithm deal with null values?
- If you look at an implementation of this algorithm in a common library, what are all the optional arguments? Of these arguments, which are typically treated as hyperparamters? Start to make a list of them and write yourself a sentence or two explaining what they each do.
- How do people typically visualise the results of this algorithm?
- How do you deal with underfitting and overfitting for this algorithm?
- How robust is this algorithm to changes in the data?
It can be a lot but take it one step at a time. Better yet, make yourself a GitHub repository and keep track of your work in a markdown file. On the subject of which…
Getting a GitHub
Get yourself a GitHub! At some point, you’ll probably need to do some work outside your school or work hours. Maybe you’re preparing for interviews, maybe you just need to learn a new topic, maybe you’ve become slightly obsessed with cubes and you want to make a cuboidal game world. Whatever it is, put it up on GitHub. What you put there doesn’t need to be perfect, and it’s a great way to show growth over time. Just having a GitHub makes you stand out. I’ve been told by some people that recruiters are encouraging them to remove their GitHub from their CV, which I find baffling. I always click through to see a GitHub when someone puts it on their CV.
Writing Your CV
I look through a lot of CVs. If I’m totally honest, I have to look at most of them pretty fast. I have a few tips to improve your CV, particularly when someone like myself is running through a lot of CVs at top speed.
Coding Languages
List the coding languages you know, even if it’s only a few! One thing that’s really helpful is to give yourself a score on each of those languages. A visual representation (like so) is particularly nice. The challenge, of course, is how exactly you rate yourself. I will caution that if you claim to be an expert in a language but your code is poor in a take-home task, it’s not a great reflection. Try to be realistic, and bear in mind that people don’t expect you to know everything! Especially if you’re applying for a more entry-level position, you don’t need to have mastered anything yet.
A nice way to offset this is to think about some of the more complicated things you know how to do in a language and list them. If you tell me you know for loops in python, I’ll assume you’ve just started. If you’re making your own python packages, I’ll assume you’ve been at it for a while. I wouldn’t do this for every language, but maybe add in something for a language you know particularly well, or that you think is especially relevant.
Specific Projects
I can learn a lot more about where you’re at with data science by seeing specific examples of project work. A lot of people just throw out a laundry list of algorithms they know and it’s really hard to know what that means. One person who lists convolutional neural networks may have watched a video about them once, whereas another person may have implemented a CNN from scratch. The more you can explain specific project work, the more context I have when I’m reading your CV.
Also, if you list an algorithm, be ready to talk about it in an interview!
Read Part 2 “Starting Your Data Science Career – Writing Better Code“
Share

{kind=link}