
Large language generative models have been used in domains such as computer vision and natural language processing for years. But for financial companies analysing transactional data, regulation, scarcity of data and cost has meant that they still rely on supervised learning with manually crafted features and decision trees. The result is a continued lack of personal understanding of their consumers at automated touchpoints, leading to minimal progress in combating fraud, credit defaults, low levels of loyalty and more. Everyone in the value chain loses out – banks, merchants and consumers.
That is, until now. Featurespace, with the launch of TallierLTMTM, is set to revolutionise how financial institutions interact and build relationships with their consumers. It begins with the greatest problem that all banks and payment providers face – card fraud. TallierLTMTM’s simple integration into current systems as a data integration API call-out can upgrade your system fast. With results from pretrained models showing improvements of around 70% in fraud value detection, TallierLTMTM is shifting the balance in the push to eradicate card fraud.
But the effort does not stop there. TallierLTMTM is fast becoming the pathway to a stronger understanding of consumer behaviour that will be capable of so much more. Solving the problems of money laundering, credit default detection, customer churn and forecasting future expenditure could be just around the corner.
Catching more fraud with less consumer friction
The advancement of technology has been significant in so many ways for financial institutions. But during that process, personalisation in financial services has gotten lost. With all touchpoints automated and everything done online, the understanding of what consumers actively do and care about has disappeared.
TallierLTMTM helps banks better understand the semantic relationships of the transactions consumers make, their journeys and actions. It goes beyond what self-supervised models have done for language because it analyses who a consumer is as an individual. TallierLTMTM is heralding a paradigm shift in how financial institutions can rebuild relationships with their consumers.
With card fraud expected to total $397.4bn over the next 10 years, 42% of which is anticipated in the US, removing the bad actors from this segment is TallierLTMTM’s primary focus.
Why hasn’t this been done before?
Modern financial systems use machine learning models to spot fraud and predict customer churn. Most of these models rely on supervised learning, where the system learns from labelled data. However, the success of large self-supervised generative models, which have proven effective in language processing, such as ChatGPT, has not previously been applied to complex financial transactions.
But why? The reason is that, as a highly regulated industry, it is incredibly difficult to access the huge amount of financial data, from enough sources, on the scale required to produce self-supervised models. Furthermore, those who have attempted to adapt language models to a transaction-based system have been met with limited success.
The experienced team at Featurespace has overcome these challenges. It has:
- Performed large scale pretraining on a model using data from 180 issuing banks containing 5.1bn transactions and
- Used its experience of training successful deep learning models on transactional data to develop an algorithm that sharply improves the value detection rate at high precision thresholds.
The result is TallierLTMTM, a generative AI Large Transaction Model (LTM) that not only focuses on the communications that people make, but their actions too. This is a significant step forward that will aid financial services and payments companies to enhance consumer protection across a range of downstream tasks, in a world where criminal attacks and subsequent financial losses continue to rise.
How does it work?
The methodology built into TallierLTMTM is driven by a new self-supervised learning approach called NPPR. It has two parts:
- Next Event Prediction (NP)
The algorithm evaluates each transaction, but not just on their own merits. It investigates both current and previous transactions to build a recurrent neural network, developing a memory and state for every individual sequence of transactions. Each consumer will therefore develop its own network of transactions, which are stored, analysed and kept alive by the bank. The system then takes the raw data, converts it into a set of machine-readable embeddings (the encoder) and then based on these, attempts to predict what the next transaction is (the decoder). Importantly, the system learns as any corrections flow back through the decoder into the encoder.
- Past Reconstruction (PR)
In reconstructing what the next event would be, the above architecture alone provides a reasonable level of performance. However, the more complex and longer the transaction sequence becomes, the system increasingly develops a short-term focus. But with the introduction of Past Reconstruction, the encoder is guided to focus more on long-term behavioural sequences, enhancing the predictive performance of future transactions. By fine-tuning the weighting of PR, depending on the downstream task, performance is maximized. Findings highlight that only a little PR influence is required to encourage longer term memories to flow through the encoder.
What are the results?
The above methodology was used to pretrain a Foundation Purchasing Model on a huge dataset of 180 European issuing banks. These were then used to create transaction embeddings for three separate issuer datasets that were not part of the initial training data, which also operate in different countries to any of the pretraining issuers.
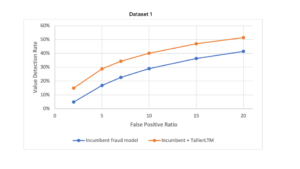
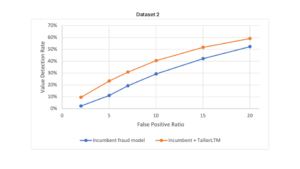
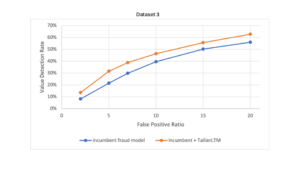
The figure below highlights the evaluations of the fraud detection models on the three datasets. Note:
- The curves in the chart show the trade off that banks need to make between the false positives that occur for genuine customers, relative to providing protection and de-risking the impact of fraud.
- The blue line shows the baseline, used from an industry standard fraud prevention model.
- The orange line shows the baseline level plus the pretrained NPPR.
The results show that by incorporating TallierLTMTM into the system, up to 71% of additional value of fraud was captured by the model, relative to the baseline, when operating at an industry-typical 5:1 false positive ratio.
In addition, the method used proved to be more effective than alternative methods in multiple classification and regression tasks, using evaluations on public datasets. The embeddings were also able to capture meaningful similarities between merchant category codes.
Reducing fraud with an instant upgrade
Many financial institutions are often plagued by the legacy systems they have had in place for years, sometimes decades. But the implementation of something new can be, understandably, risky, in terms of replacement, resources and cost. Especially so if you’re tearing up a working platform simply in the hope of something better.
That’s why Featurespace has minimised these risks. By operating as an API call-out, TallierLTMTM fits in as an additional input into virtually any existing model, resulting in an instant upgrade to your system. Enriched, valuable data with no ‘rip and replace’ required.
How much additional fraud could your organisation catch by adding TallierLTMTM to your existing system?
Featurespace is currently taking out development licences with banks and financial payment providers globally. Get in contact and take the opportunity to build something better for you and your customers.
Share
