
Take me to...

Senior Data Scientist
Milly is a Senior Data Scientist at Featurespace. She joined in August 2019; during her time at Featurespace her focus has been on fraud detection in card datasets, she has also worked on anti-money laundering, as a data science consultant, and as a mentor to newer data scientists and interns. Milly has contributed to some of Featurespace's biggest projects, helping to fight fraud and financial crime around the world. She loves tackling new challenges, and has been described by colleagues as "the queen of continuous improvement". Her background is in physics and neuroscience, which she studied at MIT and the University of Cambridge, respectively. She transitioned from neuroscience into computational neuroscience and then into machine learning, which brought her to Featurespace. Outside of work, Milly is an enthusiastic beekeeper and loves playing music, gardening, gaming, and most of all spending time with her husband and her dog, Jesse.
Deep neural networks are notoriously expensive to train (and retrain), particularly those with recurrent connections. Recurrent networks have memory, which is to say that they retain information about past transactions. This can dramatically increase the computational demands of retraining, because you have to learn about not just the present but also the past. Perhaps even more importantly, recurrent connections can make retraining a dangerous operation. What if your retraining process alters or erases your memories of the past? One of the most common problems we’re asked to solve at Featurespace is finding fraudulent transactions within a large financial dataset, for example within a set of credit card transactions. Transactional data might include information such as a card number, the amount spent on the card, the date and time of the transaction, and the merchant where the transaction took place.
For a particular card, we might construct a memory of where that card has been: what merchants has it interacted with? How much does it typically spend? What times of day does it tend to transact? If our memories of this card are degraded, we lose the ability to extract information from its past behaviour. It was essential to tackle this challenge when constructing our Automated Deep Behavioural Networks, which are deep neural networks with recurrent connections. In this article, I will attempt to guide the reader through some foundational context (deep neural networks, recurrent neural networks, and transfer learning) and then move to our approach to retraining deep neural networks in the context of real-time transactional data.
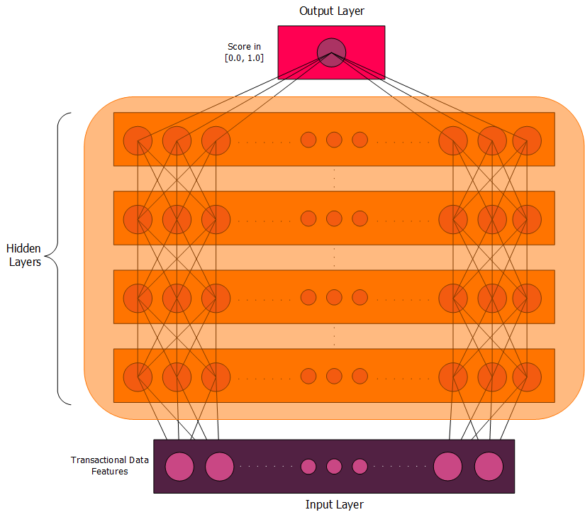
Figure 1. Structure of a typical deep neural network. Note that only a few nodes at the edges are illustrated, with smaller nodes in the centre standing in for an unspecified number of additional nodes. For simplicity, all hidden layers are given the same width, though this is not necessarily the case in practice. The choice of four hidden layers is arbitrary; deep neural networks can have as few as two hidden layers and as many layers as the data and computational power can support. The full connectivity is not captured for reasons of readability, but the reader is asked to kindly imagine the additional connections between nodes.
Deep neural networks are described as “deep” because they contain some number of so-called hidden layers between their input and output layers. Each hidden layer takes features from a preceding layer as input, and outputs new, higher-level features. In the case of finding fraud in transactional data, the input layer consists of features we have built from the transactional data, and the output layer contains a single node (also called a neuron) that generates a score between 0 and 1. Scores near 0 indicate a very low probability of fraud, while those near 1 indicate a very high one. Between those two layers lie a number of hidden layers that extract patterns from the transactional data, building up a picture of how individuals and institutions spend money.
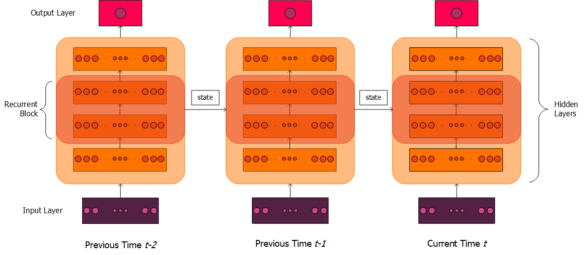
Figure 2. Schematic illustration of a recurrent neural network, following on from Figure 1. Connections between nodes have been omitted, and are instead broadly captured by arrows between whole layers. Recurrent connections (left to right) pass information from the recurrent block at a previous timestep to the recurrent block at the next timestep. This information is collectively referred to as "state". For illustrative purposes, only two previous timesteps are shown. A single neuron is shown in the output layer, as in our use case, though more are certainly possible in a general case.
Before diving into the specifics of our Automated Deep Behavioural Networks, it is useful to have a good understanding of two key terms: “stateful” and “recurrent”? We have said above that a recurrent model has memory, but what does that mean more concretely? I will borrow (with slight modification) an example from my colleague Alec’s article on feature stores, in which he considers the feature averageAmountSpentOnCardOverLastMonth. We would call this feature “stateful” in the sense that we cannot find its value using just the information in the current transaction. Instead, we need to keep some kind of historical record. The memory past transactions that a model retains can be more formally described as “state”.
The deep neural network I have illustrated in Figure 1 cannot capture stateful information. It only takes in the features from the current transaction, and has no knowledge of the transactions that came before. The solution to this problem is the recurrent neural network, which was designed to understand sequential data. Rather than just receiving information from the layer below it, nodes in a recurrent neural network (RNN) also receive stateful information from the network at a previous point in time. In general, recurrent networks will not include recurrent connections in every layer, but instead have a dedicated recurrent layer (or layers) that we describe as a recurrent block. This block takes as input not only information from the current transaction, but previous values in the block.
For example, suppose we have a node in our recurrent block that calculates the value of averageAmountSpentOnCardOverLastMonth. It might take an input such as the amount of the current transaction (let’s say $100), which it receives from a lower layer. It must also know the value of this feature the last time the card was used (let’s say $10). This stateful information must be passed from a recurrent connection, which provides the value of the same node at a previous timestep (the last time the card was used). The new value of the feature will become $100, which must again be passed via a recurrent connection the next time this same card is used.
The structure of a recurrent neural network is illustrated schematically in Figure 2. Note that, for this to be meaningful in our example of averageAmountSpentOnCardOverLastMonth, the “previous times” t-1, t-2,… cannot simply be the most recent transactions in the dataset but rather need to represent previous transactions on the same card. We would therefore describe this recurrent layer as being “scoped” on the card.

One of the most common problems we're asked to solve at Featurespace is finding fraudulent transactions within a large financial dataset
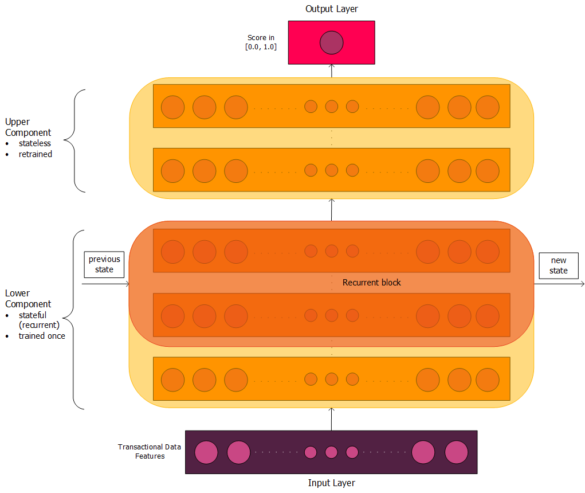
Figure 3. High-level structure of Featurespace's Automated Deep Behavioural Networks, continuing on from Figures 1 and 2. The diagram is not representative of the exact number of layers in the lower and upper components, but rather is intended to give a general sense of the architecture. Connections between nodes are not included, partly for clarity and partly because the network is not everywhere fully dense and connected. The lower component includes a recurrent block, which takes in state from the "scoped" previous timestep. As with Figure 1, the width of the layers should not be assumed constant throughout the network.
The hidden layers of our Automated Deep Behavioural Networks can best be thought of in terms of two broad structures: a lower component and an upper component. The lower component is stateful, which it achieves by including recurrent connections. The states are constantly updated as new data appears, but the relationships are assumed to be sufficiently fundamental that their connection weights should be consistent over time. The lower component is designed to capture underlying relationships in the dataset, and is trained only once. In contrast, the upper component is stateless, and can be retrained as needed. It captures high-level patterns, focusing on the specific ways in which fraud appears in the dataset at the time of training.
This approach is a specific implementation of transfer learning we might call self-transfer learning. By way of analogy, let us consider a transfer learning scenario from natural language processing (NLP): the problem of training a machine learning model to write a new chapter of a book. This is most commonly done in two phases. First, a source model is trained on a huge volume of text, something like English-language Wikipedia. This model is trying to understand the grammar and vocabulary of the English language, which is an expensive training task. It is then “transferred” to the specific task at hand, by adding new layers on top of the first model. These new layers form a second model, called the target model, which is only trained on the text in question. If we were to say we wanted our target model to write a scene in Shakespeare’s Twelfth Night, it would be up to this second model to capture Shakespeare’s writing style and the specifics of the play — drawing on the understanding of English provided by the source model. Because the problem it’s trying to solve is much narrower, the target model can train on a much smaller volume of data.
In the same way, the lower component of our model is designed to capture broad principles that should be consistent over time. How do you know if a previous transaction was approved? How do you know if two merchants are similar? How do you measure the value of a typical genuine transaction for a card in your dataset? These relationships are the grammar and vocabulary of the dataset. In contrast, the upper layer is using that context to understand where fraud exists in the dataset at the time of training. What types of merchants are particularly risky? What modes of payment are most suspicious? How much do people deviate from typical transaction values when committing fraud?
Because the specifics of fraud are constantly evolving, we need to anticipate concept drift in our customers’ data. Fraud goes through trends, whether due to a global pandemic or new strategies from organised groups of fraudsters. Regular retraining allows us to react quickly to these changes, relying at each step on the source model to give us a strong starting point from which to train the target.

Now that we’ve discussed transfer learning more generally, we can understand the self-transfer learning performed by our Automated Deep Behavioural Networks. In contrast to traditional transfer learning, the lower component is not aiming to understand all types of transactional data. It is built to generalise to the same dataset over time, rather than to entirely new datasets.
To continue our NLP analogy, we are not so much training our lower component on the entirety of Wikipedia as on the works of Shakespeare. This is an expensive process requiring a lot of data, but not nearly as expensive as if we wanted a source model that understands the breadth of English. We could compare training our upper component on new data to training the target model on a new play. If we trained our target model on As You Like It, we expect it to perform well. However, if we trained it on Oscar Wilde’s The Importance of Being Earnest, we expect disappointment. Likewise, we expect retrains of our upper component to work well for new data in the same dataset, but we would not transfer our lower component to an unseen dataset.
In our Automated Deep Behavioural Networks, the lower component is tailored to a specific labelled dataset, with the aim of understanding how money moves within that data. The scope of our transfer is much narrower, because we are training our upper and lower components on the same dataset (at different points in time). In addition, this is not traditional transfer learning in that the upper and lower components are not distinct source and target models. Rather, we would describe them as two pieces of the same model. For these reasons, we refer to our approach as self-transfer learning.

In our Automated Deep Behavioural Networks, the lower component is tailored to a specific labelled dataset, with the aim of understanding how money moves within that data.
Our training approach allows us to create deep neural networks that can work with and adapt to transactional data in the real world. We can retrain our models to account for concept drift, so that our models understand not just what fraud means broadly but what it means today. At the same time, our retrains are lightweight enough that they are practical in production. We can retrain without damaging or destroying our historical state, while allowing the stateful information to be updated by the latest events.
Automated Deep Behavioural models have given us our best performance yet, and we’re very excited to bring them to our customers. Ultimately, our goal is to build models that can pinpoint fraud in enormous real-time datasets, making financial crime less lucrative for perpetrators and less damaging for victims. Fraud is always changing, and we need models that are complex enough to understand how money moves but agile enough to react to the latest trends. Our approach to training deep neural networks for real-time transactional data is an important innovation in the process of making the world a safer place to transact.

